By Nikolay Laptev, Saeed Amizadeh, Youssef Billawala
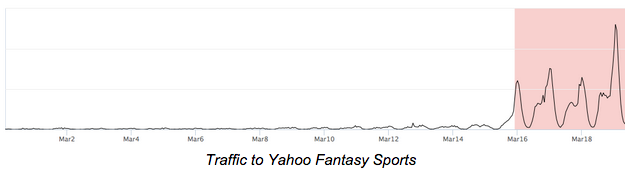
We’re in the middle of an anomaly. It’s March Madness and that means that we’re seeing an abnormally large amount of traffic to Yahoo Fantasy Sports. We anticipated this anomaly (and you probably could have guessed it too)–but what about far more serious abnormalities that no one could anticipate? What about those anomalies that indicate potential security threats to our user’s data?
At Yahoo, we take such scenarios very seriously. As such, the Media Sciences team at Yahoo Labs has researched new ways to detect such anomalies in data streams over time (aka time series). We’ve developed new algorithms that detect fewer false anomalies in order to aid service engineers looking to improve user experience and security. To test and validate these algorithms, we created a large dataset that allowed us to meaningfully iterate and improve our work. Now we are making this dataset available to the public via our Webscope data-sharing program.
An anomaly, or an outlier, is a data point that is significantly different from the rest of the given data. The amount of data collected from user activity and server logs is growing at an ever-increasing speed and the ability to monitor it and protect it is critical. Due to the large volume of this data, automatic anomaly detection has become increasingly important in industry and the research community across areas such as fraud, network intrusion detection, and server monitoring [1,2,3]. There are many anomaly detection algorithms; however, there is no standard, wide-spread benchmark dataset against which anomaly detection models can be judged.
As a company with vast amounts of data, and in an effort to promote collaboration among colleagues working in this critical field, we are releasing the first-of-its-kind dataset consisting of time series with labeled anomalies. By open sourcing this dataset, we hope anomaly detection researchers will be put on equal footing so that when new models are developed, they are tested and compared on the same standard data.
Part of the dataset is synthetic (i.e., simulated) and part of the dataset is based on real traffic to Yahoo services. While the anomalies in the simulated dataset were algorithmically generated, the anomalies in the real-traffic dataset were manually labeled by editors and are thus prone to human interpretation and human error. These datasets are evolving and more time series will be added in the near future.

Our incentive to release the benchmark dataset for anomaly detection is motivated by similarly spirited efforts made in the time series forecasting domain. In particular, there are widely accepted standard benchmarks for time series forecasting such as the dataset developed by Makridakis and Hibon and popularized by Rob Hyndman [4]. These benchmarks allow for standard comparison across many forecasting models which in turn speeds up research iteration and ultimately shortens the time for companies to launch forecasting models in production. Furthermore, the Makridakis and Hibon dataset has arguably been the single most important tool allowing fast yet thorough collaboration among researchers, and has resulted in many of the forecasting insights that we use today at Yahoo.
Following the successful work done as a result of their dataset, we hope the release of our follow-on dataset of time series anomalies will similarly catalyze progress in the anomaly detection domain, both in terms of pure scientific research and in terms of production cycles stemming from applied industrial development.
[1] https://blog.twitter.com/2015/introducing-practical-and-robust-anomaly-detection-in-a-time-series
[2] https://m.facebook.com/notes/protect-the-graph/anomaly-detection-using-osquery/1532788613627951/
[3] http://www.metaforsoftware.com/#anomalydetection
[4] http://robjhyndman.com/software/mcomp/
 mobile
mobile