 Yahoo Labs is honored to have hosted Dr. Andrew McCallum on Tuesday for a quarterly #BigThinkers seminar. In his talk, Dr. McCallum, Professor and Director of the Information Extraction and Synthesis Laboratory in the School of Computer Science at University of Massachusetts Amherst, discusses a wealth of research regarding the construction of probabilistic databases for large-scale knowledge bases.
Yahoo Labs is honored to have hosted Dr. Andrew McCallum on Tuesday for a quarterly #BigThinkers seminar. In his talk, Dr. McCallum, Professor and Director of the Information Extraction and Synthesis Laboratory in the School of Computer Science at University of Massachusetts Amherst, discusses a wealth of research regarding the construction of probabilistic databases for large-scale knowledge bases.
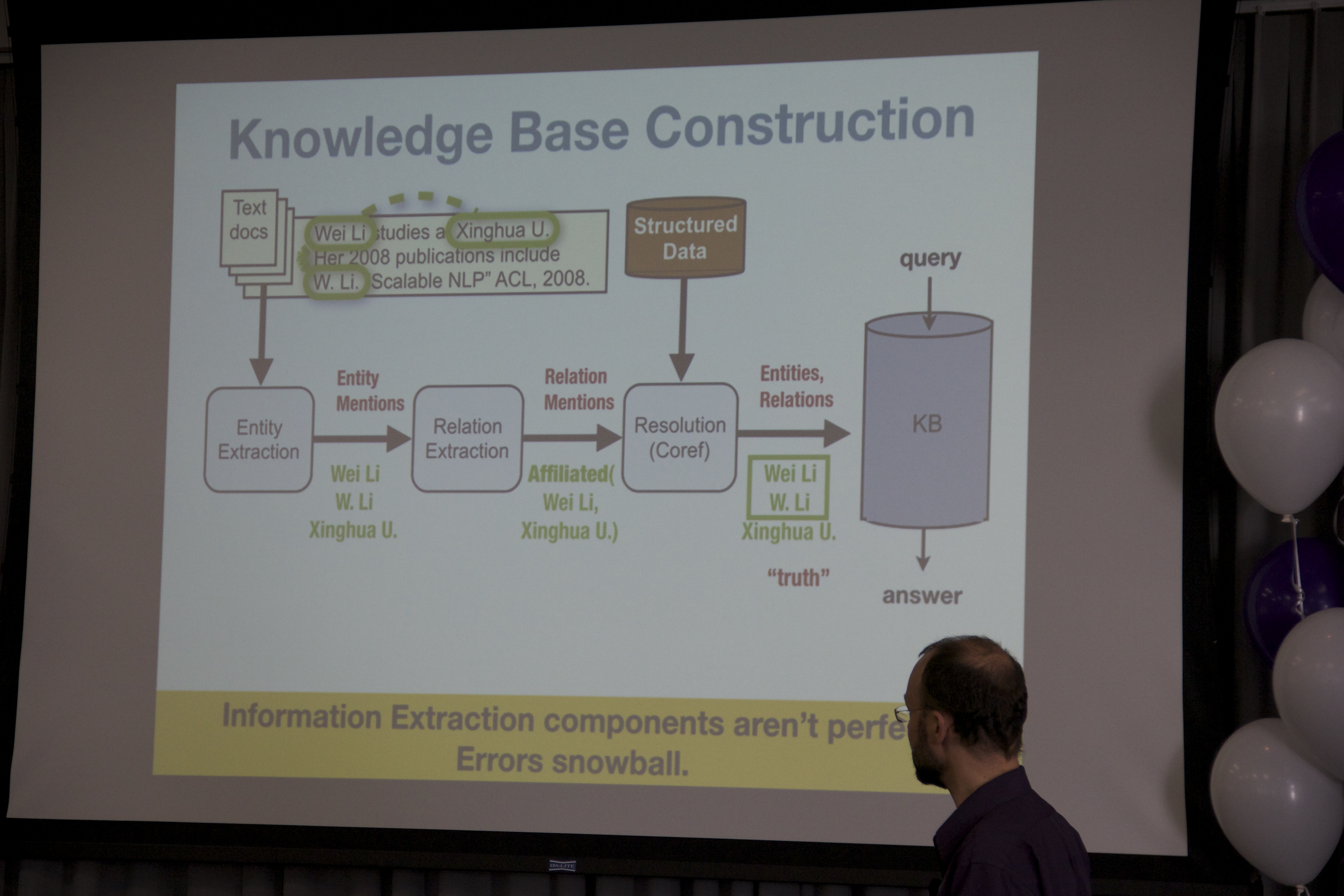
McCallum contends that building large-scale knowledge bases enables reasoning about the underlying entities and relations in the world rather than irregular text spread across the web. For this reason, he says, knowledge base construction and maintenance have been of increasing interest in both industry and academia. During his talk, McCallum describes scalable machine learning methods for managing uncertainty throughout the information extraction and integration pipeline, parallel-distributed entity resolution, and an exciting new way to represent and align large, rich schema semantics based on matrix factorization and vector embeddings.
The event was broadcast live on our
labs.yahoo.com homepage and viewers had the opportunity to ask questions and comment on our Twitter stream
@YahooLabs as well as our
Facebook page.
If you are interested in learning about probabilistic databases for large-scale knowledge base construction, you can view Dr. McCallum's full presentation here:
ABSTRACT
When building large-scale knowledge bases we want to account for uncertainty in order to perform joint inference and accurately integrate new evidence. However, reasoning about data at this scale quickly involves more random variables than can fit in machine memory. For this reason we have become interested in probabilistic databases, which we use not only for storing and querying the results of an information extraction (IE) system, but also for aiding the performance of IE joint inference itself---managing the many random variables and intermediate results of IE. In this approach only raw textual and tabular evidence is presented to the database, and IE inference is performed "inside the database." Thus we have taken to calling this an Epistemological Database, indicating that the database doesn’t directly observe the truth about entities and relations; it must infer the truth from available evidence [VLDB 2010; AKBC 2012]. After describing these ideas I will present two pieces of recent work: first, large-scale, non-greedy, Monte Carlo entity resolution running with distributed processing, which also supports probabilistic reasoning about crowd-sourced human edits; and second, an approach to "schema-less" relation extraction based on tensor factorization which we call "universal schema." All of the above are implemented on top of our probabilistic programming framework FACTORIE, a Scala library for factor graphs and natural language processing.
Joint work with Michael Wick, Sameer Singh, Karl Schultz, Sebastian Riedel, Limin Yao, Ari Kobren, Luke Vilnis and Gerome Miklau.
BIOGRAPHICAL NOTE
Andrew McCallum is a Professor and Director of the Information Extraction and Synthesis Laboratory in the School of Computer Science at University of Massachusetts Amherst. He has published over 250 papers in many areas of AI, including natural language processing, machine learning, data mining and reinforcement learning, and his work has received over 38,000 citations. He obtained his PhD from the University of Rochester in 1995 with Dana Ballard and a postdoctoral fellowship from CMU with Tom Mitchell and Sebastian Thrun. In the early 2000's he was Vice President of Research and Development at WhizBang Labs, a 170-person start-up company that used machine learning for information extraction from the Web. He is a AAAI Fellow, the recipient of the UMass Chancellor's Award for Research and Creative Activity, the UMass NSM Distinguished Research Award, the UMass Lilly Teaching Fellowship, and research awards from Google, IBM, Yahoo, and Microsoft. He was the General Chair for the International Conference on Machine Learning (ICML) 2012, and is the current president of the International Machine Learning Society, as well as member of the editorial board of the Journal of Machine Learning Research. For the past ten years, McCallum has been active in research on statistical machine learning applied to text, especially information extraction, entity resolution, semi-supervised learning, topic models, and social network analysis. His work on open peer review can be found at
http://openreview.net. McCallum's web page is
http://www.cs.umass.edu/~mccallum.
YAHOO LABS BIG THINKERS SPEAKER SERIES Yahoo Labs is proud to bring you its 2015 Big Thinkers Speaker Series. Each year, some of the most influential, accomplished experts from the research community visit our campus to share their insights on topics that are significant to Yahoo. These distinctive speakers are shaping the future of the new sciences underlying the Web and are guaranteed to inform, enlighten, and inspire.
 Yahoo Labs is honored to have hosted Dr. Andrew McCallum on Tuesday for a quarterly #BigThinkers seminar. In his talk, Dr. McCallum, Professor and Director of the Information Extraction and Synthesis Laboratory in the School of Computer Science at University of Massachusetts Amherst, discusses a wealth of research regarding the construction of probabilistic databases for large-scale knowledge bases.
Yahoo Labs is honored to have hosted Dr. Andrew McCallum on Tuesday for a quarterly #BigThinkers seminar. In his talk, Dr. McCallum, Professor and Director of the Information Extraction and Synthesis Laboratory in the School of Computer Science at University of Massachusetts Amherst, discusses a wealth of research regarding the construction of probabilistic databases for large-scale knowledge bases.


 mobile
mobile