by David Carmel, Avihai Mejer, Yuval Pinter, and Idan Szpektor
Search engines apply hundreds of signals to estimate the relevance of search results to a user’s query. One of the most important signals is the occurrence of the query terms among the documents. Previous studies have shown that term weighting, i.e., determining the relative contribution of the terms in the query and the documents to relevance estimation, is crucial for the performance of search engines, and an abundance of weighting schemes have been proposed and studied throughout the years. The common belief in the Information Retrieval (IR) community is that statistical analysis, mostly based on term counts, is satisfactory for providing highly effective term weighting for retrieval.
While many attempts have been made in the past to enrich statistical methods for term weighting with linguistic analysis methods, standard Natural Language Processing (NLP) methods such as morphological analysis, part-of-speech tagging, dependency parsing, etc., failed to show significant improvement over statistical methods. It has therefore become widely accepted in the IR community that the impact of linguistic methods on term weighting is marginal, and that the expected contribution to retrieval, if any, compared to the computational cost, is not justifiable.
In a paper published in the proceedings of the ACM International Conference on Information and Knowledge Management (CIKM 2014) this week, we hypothesize that the low impact of NLP-based term weighting methods for retrieval could be attributed to the length of queries. Queries that most IR systems deal with, especially on the Web, are very short (about 2.4 terms on average). For such queries, the appearance of the search terms in the document is a strong enough indication to its relevance to the search. However, not all queries are short, and long queries can potentially benefit from linguistic analysis as the syntactic roles of the terms, and their inter-relations, affect their relative contribution to relevance estimation.
As a test-case, we analyzed a vertical search scenario where the search engine issues the query against several sub-domains (verticals) in addition to searching over the general Web. We focused on the Yahoo Answers (YA) vertical since typical Web queries submitted to YA are longer and contain more content than general Web queries, and are therefore likely to benefit from syntactic analysis of the documents. Figure 1 below shows the length distribution of Web queries submitted to YA by general purpose search engines. About 70% of the queries have 5 words or more. We emphasize that these queries, though longer, are still typical Web queries in contrast to natural language questions that are submitted directly to YA, which are explicitly meant to be answered by humans.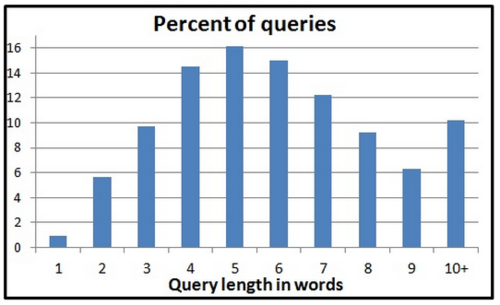
Figure 1: The length distribution of Web queries submitted to YA.
Take for example the Web query “american pie like,” in relation to the YA question texts t1=“Is college life really like in american pie?” and t2=“Who else here doesn't like american pie?” Looking at the query, with respect to term counts, and even when considering word proximity, there is no strong preference to either of the texts. Yet, in the first question the term like functions as a preposition, while in the second question it functions as a verb. Our model gives higher weight to verbs than to prepositions and therefore ranks the second question higher. To test our hypothesis, we applied part-of-speech (POS) tagging and dependency parsing (DP) to candidate CQA documents, and included the POS categories and syntactic roles of query terms as factors affecting their relative importance for retrieval. As an example of this process, consider the YA page with the question title “Where do I buy fresh almonds?” The POS tags and dependency parse tree for this title are shown in Figure 2. The term fresh in the title is tagged with the POS tag “adjective” and has the syntactic role “adjectival modifier,” meaning it acts as a modifier to the noun almonds. In a similar manner, the term almonds was tagged with NNS (“plural noun”) and has the syntactic role direct object.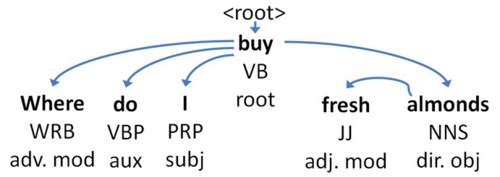
Fig 2: POS tagging and dependency parse tree for the question “Where do I buy fresh almonds?” The upper label of each token is its POS tag and the lower label is its syntactic role.
Our proposed weighting model incorporates both statistical information and syntactic information of the term, learning the relative importance of each signal using learning-to-rank techniques on a collection of query/clicked-page pairs. We note that POS and DP have already been used for IR tasks. Yet, these approaches parse the query, and are therefore limited to natural language queries, for which syntactic analysis of the query is feasible and reliable. In contrast, our model is based only on document content analysis and therefore can be computed offline during indexing time, while efficiently applied for any query online. Figure 3 shows the precision results for several ranking models, broken down by query length. The baselines are BM25, a statistical based ranking function, and LETOR, which is a state-of-the-art ranking function based on many statistical features (including BM25), optimally tuned by learning-to-rank. The pos+dp curve represents the performance of the ranking function based on syntactic features combined only with BM25, while the all curve represents a combination of all statistical and syntactic features. For short queries, with one, two, and even three terms, syntactic analysis does not help to improve the ranking quality. This result echoes the common knowledge in IR for the inadequacy of NLP for short queries. The situation is reversed for queries with 4 terms or more. Specifically, there is consistent improvement when adding syntactic features on top of LETOR features. This improvement is statistically significant.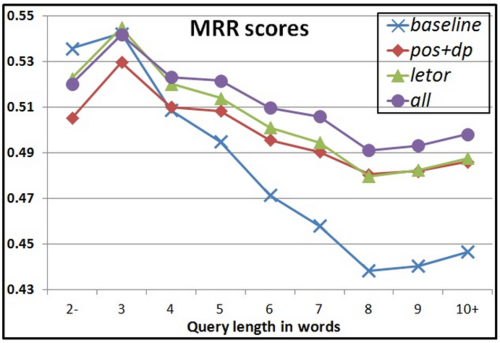
Fig 3: Precision (MRR) of various ranking models, broken down by query lengths. Label 2- refers to queries of length 1 and 2. Label 10+ refers to queries of length 10 and above.
We see this work as a first step towards showing the benefit of advanced NLP techniques for search tasks. In future work, we would like to investigate the effect of our term weighting approach in other domains, such as news and blogs. We are also interested in testing the contribution of semantic analysis, such as semantic role labeling, for the task of term weighting.
 mobile
mobile