by David A. Shamma Today the photograph has transformed again. From the old world of unprocessed rolls of C-41 sitting in a fridge 20 years ago to sharing photos on the 1.5" screen of a point and shoot camera 10 years back. Today the photograph is something different. Photos automatically leave their capture (and formerly captive) devices to many sharing services. There are a lot of photos. A back of the envelope estimation reports 10% of all photos in the world were taken in the last 12 months, and that was calculated three years ago. And of these services, Flickr has been a great repository of images that are free to share via Creative Commons. On Flickr, photos, their metadata, their social ecosystem, and the pixels themselves make for a vibrant environment for answering many research questions at scale. However, scientific efforts outside of industry have relied on various sized efforts of one-off datasets for research. At Flickr and at Yahoo Labs, we set out to provide something more substantial for researchers around the globe.
 Data, data, data... A glimpse of a small piece of the dataset.
Data, data, data... A glimpse of a small piece of the dataset.
 YFCC100M by aymanshamma on Flickr.
YFCC100M by aymanshamma on Flickr.
photo_id, a jpeg url or video url, and some corresponding metadata such as the title, description, title, camera type, title, and tags. Plus about 49 million of the photos are geotagged! What’s not there, like comments, favorites, and social network data, can be queried from the Flickr API.
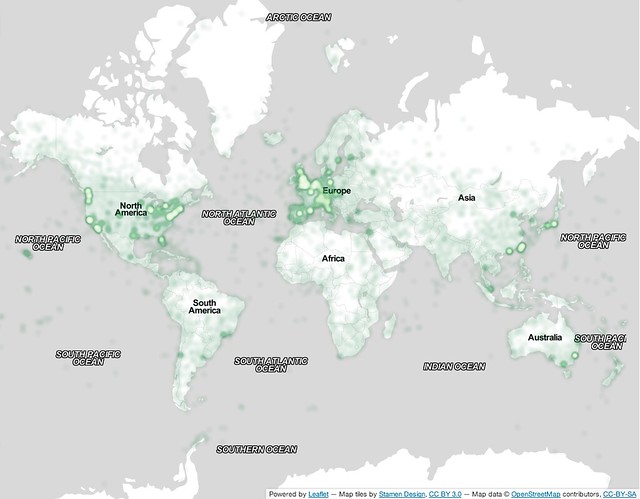 A 1 million photo sample of the 48 million geotagged photos from the dataset plotted around the globe.
One Million Creative Commons Geo-tagged Photos by aymanshamma on Flickr.
A 1 million photo sample of the 48 million geotagged photos from the dataset plotted around the globe.
One Million Creative Commons Geo-tagged Photos by aymanshamma on Flickr.
† In case you're curious: SIFT, GIST, Auto Color Correlogram, Gabor Features, CEDD, Color Layout, Edge Histogram, FCTH, Fuzzy Opponent Histogram, Joint Histogram, Kaldi Features, MFCC, SACC_Pitch, and Tonality.

 mobile
mobile