Every time you access the Yahoo homepage or a Yahoo digital magazine on mobile or desktop, content personalization systems behind the scenes optimize your experience by ranking the available content by relevance for you. The produced recommendations are based on the system’s knowledge about your preferences–for example, your reading habits. Every visit of a known user, therefore, translates to a lookup of her personalized model by some unique user id, performed by the ranking algorithm. Likewise, every user action triggers a background update of this user’s model. Conceptually, the entire system is based on a huge persistent map that associates user ids (keys) with their properties (values). This map is called key-value store, or simply KV-store.
At Yahoo, the Sherpa cloud KV-store service is indispensable for major content and ad personalization products. Sherpa supports over a billion users and runs on thousands of nodes spread across multiple, geo-distributed datacenters. The core building block behind this service is a local KV-store used to power a single node. Sherpa employs the popular open-source RocksDB library (an incarnation of the earlier LevelDB), which is considered to be a state-of-the-art local KV-store technology.
To provide a real-time end-to-end experience, data retrieval (read) and update (write) latencies at a local KV-store should be very small (low milliseconds in most cases). High throughput is also essential, in order to exploit the hardware efficiently and eventually reduce the cloud service footprint. In order to improve the best-in-class performance of of local KV-stores, we set out to scale them up on modern multi-core hardware.
The secret sauce behind modern KV-stores, including RocksDB, is their log-structured-merge (LSM) design, which is optimized for write-heavy workloads, as is typical for systems in which data is generated at a very high pace. LSM KV-stores buffer writes in a fast (mutable) in-memory segment, and perform batch I/O to a collection of immutable on-disk segments. Each write adds a new data version to the in-memory segment (hence, the log analogy). When this data structure fills up, it is flushed to disk, either by being merged with an existing disk segment or by creating a new one. A read looks for the latest version of the key in the in-memory segment, and if it is not found, also searches the on-disk segments. Once in a while, disk segments are merged in the background to eliminate redundant versions. This paradigm substitutes expensive random writes to disk with efficient sequential I/O, and dramatically reduces the write latencies. The figure below illustrates the concept.
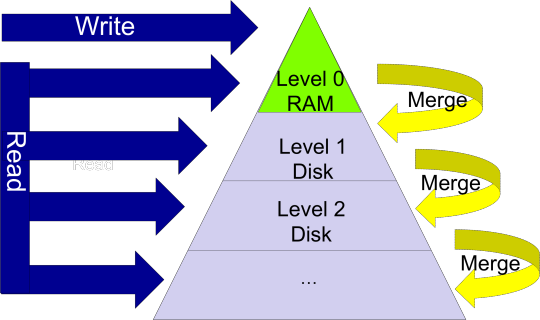
Figure 1. Log-Structured-Merge (LSM) storage.
RocksDB has become so efficient at optimizing I/O speed, that in many applications, its in-memory operations have become the performance bottleneck. Nowadays, the data access rate is usually limited by the speed of reads and writes to RAM. Today’s most popular KV-stores were designed for hardware with a relatively small number of cores, which were common in data serving farms until recently. We posited that pushing the envelope of KV-store serving rates would involve harnessing more cores, and allowing read and write operations to execute concurrently on the in-memory data structure. This is where the real fun started!
Previous KV-store solutions failed to scale up on multi-core hardware due to synchronization bottlenecks. We tackled this challenge by capitalizing on cutting-edge research on multiprocessor-friendly lock-free data structures. Since the early days of distributed computing and databases, consistency of parallel access to shared memory was guaranteed via atomic locks, which worked, but led to huge underutilization of hardware resources. This trend changed in the last decade, when novel lock-free algorithms dramatically improved utilization, driving throughput and latency beyond previous limits.
Prior research work focused on applying lock-free data structures to memory-intensive applications. These algorithms have not been used to optimize big-data platforms, which combine RAM access with disk I/O. To the best of our knowledge, our work is the first step in this direction. We infused lock-free data structures into the RocksDB internals. This was nontrivial due to the library’s rich API (get/put/snapshot scan/atomic read-modify-write) and the need to coordinate the memory and disk accesses. Many details of our algorithm, cLSM (concurrent LSM), appear in our research paper, recently presented at the EuroSys conference.
The effort paid off! We discovered cLSM outperforms the state-of-the-art LSM implementations (including RocksDB and LevelDB), improving throughput by 1.5x to 2.5x. It demonstrates superior scalability with the number of cores, successfully exploiting twice as many as RocksDB could scale up to previously. The benchmark plots below depict the evaluation for multiple workloads. Here, we compare cLSM with native RocksDB and LevelDB key-value stores, as well as two academic prototypes, bLSM and HyperLevelDB (a different offspring of LevelDB). We consider multiple workloads: write-only, read-only, read-modify-write (RMW)-only, and a mix of writes and scans. cLSM proves to also be superior on a variety of production workloads produced by Yahoo systems.
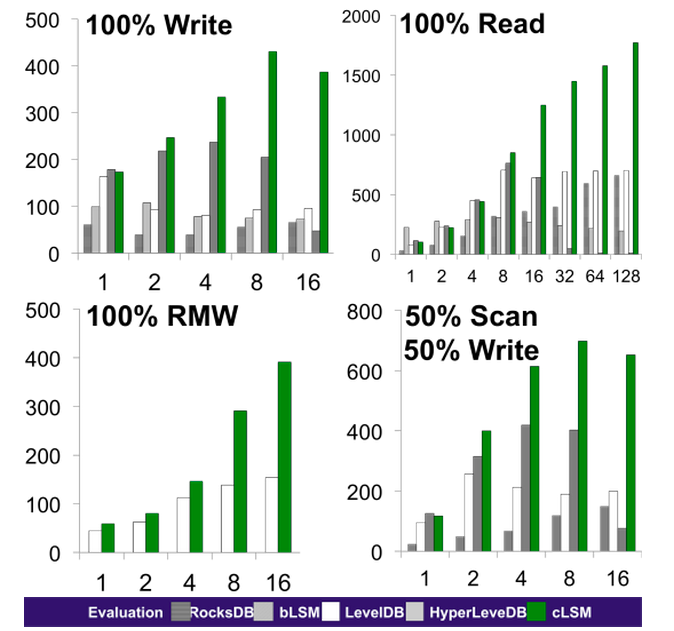
Figure 2. Evaluation - Throughput (1000′s ops/sec) vs the # of Worker Threads.
This project is joint work by Guy Gueta, Eddie Bortnikov, Eshcar Hillel, and Idit Keidar at Yahoo Labs. We are actively working with the open-source community to contribute our cLSM algorithms back to the mainstream RocksDB code. Stay tuned for more on our efforts!

 mobile
mobile